Sessions will comprise:
- Talks: Breakthrough presentations in the beginning of every day, by a notable guest (from academy or industry), complemented by open discussion with the class.
- Lessons: Traditional class sessions, provided by one or more teachers (mainly from academy, but possibly shared with a speaker from the industry); lessons will be focused on a specific technical challenge, defining it and exposing state of the art the methods and techniques to address it, as also of the related technology.
- Laboratory: Students will be arranged in working groups, which will be asked to apply the competencies acquired during the course to seek a solution to a posed problem representing a real need of a real industry.
Program |
|||
| Feb 16 | Feb 17 | Feb 18 | |
|---|---|---|---|
| 09:00 | Welcome! School Opening |
||
| 09:30 |
Talk 1 (auditorium FA1) Real-time Data Mining |
Talk 2 (auditorium FA1) Machine Learning for Robotics |
Talk 3 (auditorium FA1) IBM Watson |
| 10:30 | …break… | ||
| 11:00 |
Lesson 1 (auditorium FA1) Clean your data if you care about its quality |
Lesson 3 (auditorium FA1) Visualization of Time-Dependent Data |
Lesson 5 (auditorium FA1) Cyber-Physical Systems, IoT, and Embedded Systems |
| 12:30 | …lunch… | ||
| 14:00 |
Lesson 2 (auditorium FA1) Stream Processing: A Look Under the Hood |
Lesson 4 (auditorium FA1) Introduction to Stream Processing with Apache Flink |
Lab 3 (Laboratory 14 and support room F2) Group Work: Preparation of the reports |
| 15:30 | …break… | ||
| 16:00 |
Lab 1 (Laboratory 14)
|
Lab 2 (Laboratory 14) Group Work: Open laboratory, for work on the challenge... |
Lab 4 (auditorium FA1) Group Work: Presentation and discussion of the of results |
| 18:00 | Social Reception | Social Dinner ... School Closing! |
|
Teachers and Special Collaborations |
Sessions |
|
|
|
João Gama is Associate Professor of the Faculty of Economy, University of Porto. He is a researcher and vice-director of LIAAD, a group belonging to INESC TEC. He got the PhD degree from the University of Porto, in 2000. He has worked in several National and European projects on Incremental and Adaptive learning systems, Ubiquitous Knowledge Discovery, Learning from Massive, and Structured Data, etc. He served as Co-Program chair of ECML'2005, DS'2009, ADMA'2009, IDA' 2011, and ECML/PKDD'2015. He served as track chair on Data Streams with ACM SAC from 2007 till 2016. He organized a series of Workshops on Knowledge Discovery from Data Streams with ECML/PKDD, and Knowledge Discovery from Sensor Data with ACM SIGKDD. He is author of several books in Data Mining and authored a monograph on Knowledge Discovery from Data Streams. He authored more than 250 peer-reviewed papers in areas related to machine learning, data mining, and data streams. He is a member of the editorial board of international journals ML, DMKD, TKDE, IDA, NGC, and KAIS. He supervised more than 12 PhD students and 50 Msc students. |
Talk 1 Real-Time Data Mining Nowadays, there are applications where data is best modelled not as persistent tables, but rather as transient data streams. In this keynote, we discuss:
Data streams are characterized by huge amounts of data that introduce new constraints in the design of learning algorithms: limited computational resources in terms of memory, processing time and CPU power. In this talk, we present some illustrative algorithms designed to taking these constrains into account. We identify the main issues and current challenges that emerge in learning from data streams, and present open research lines for further developments. |
 |
Francisco S. Melo is Assistant Professor at the Department of Computer Science and Engineering of Instituto Superior Técnico, and a Senior Researcher of the GAIPS Group of the INESC-ID. He received his PhD in Electrical and Computer Engineering at Instituto Superior Técnico in 2007. Since then, he held appointments in the Computer Vision Lab of the Institute for Systems and Robotics (2007), in the Computer Science Department of Carnegie Mellon University (2008-2009) and in INESC-ID (2009). He was principal investigator of the projects MAIS+S and INSIDE (CMU-Portugal), involving interaction between humans and robots in open spaces and participated as part of the INESC-ID research team on several other projects on human-robot interaction, such as LIREC and EMOTE (EU-FP7). His research addresses problems within machine learning, particularly on reinforcement learning, planning under uncertainty, multi-agent and multi-robot systems, developmental robotics, and sensor networks. |
Talk 2 Machine Learning for robotics This talk will discuss some of the main challenges in present day robotics, and how machine learning techniques have been used to address some of these challenges. In particular, the talk will go over recent advances in robot perception, reasoning and actuation, boosted and supported by machine learning techniques. I will also describe some more recent work involving human-robot interaction. |
 |
Arlindo Dias IT Architect, IBM Cloud Services
|
Talk 3 IBM Watson "IBM Watson is a cognitive system enabling a new partnership between people and computers..." See more in Youtube: https://youtu.be/_Xcmh1LQB9I |
 |
Helena Galhardas is a tenured Assistant Professor at the Computer Science and Engineering Department at University of Lisbon (Instituto Superior Técnico - IST/UL), and a senior researcher and co-founder of the IDSS Action Line at INESC-ID. She received her Ph.D. (2001) in Informatics from University of Versailles and Saint-Quentin. Her research is focused on Data Cleaning and Integration, Extraction-Transformation-Loading, Databases and Information Extraction. Helena has participated in several projects (research and consulting) and she has authored or co-authored more than 40 peer-reviewed scientific publications. She has evaluated FP7 and H2020 project proposals. She co-chaired the Program Committee of DILS 2014 (International Conference on Data Integration in the Life Sciences). |
Lesson 1 Clean your data if you care about its qualityData cleaning is crucial to ensure that data is of good quality. In application contexts where we want to make use of data for analysis purposes, data must satisfy a set of quality requirements. In this lesson, we will first introduce the notion of data quality as an activity that encompasses two main tasks: (i) data quality assessment; and (ii) data quality improvement (or data cleaning). Second, we will explain the notion of data profiling which enables to assess the quality of a data set. Third, we will describe one of the main tasks of a data cleaning process that consists on the identification and consolidation of records that concern the same real world entity, also called approximate duplicate records. Finally, we will list some of the main data quality tools. |
|
|
Ricardo Ferreira Software Engineer and Team Leader at Feedzai. |
Lesson 2 Stream processing: A look Under the Hood Pulse, Feedzai's flagship product, is deployed in extremely demanding environments, with strict latency requirements (max 250 ms latency, 10ms at 50th percentile). Under the hood, it is powered by an event stream processing engine developed in-house to match Feedzai's needs. In this talk you'll see how Feedzai relies on it to catch bad guys and the challenges in developing and maintaining an event stream processing engine that has low latency requirements. |
 |
Daniel Gonçalves is a researcher at the Visualization and Multimodal Interfaces Group of INESC-ID and professor in the Computer Science and Engineering Department of IST, the School of Engineering of the University of Lisboa, Portugal. |
Lesson 3 Visualization of Time-Dependent DataOne of the most effective ways to make sense of a dataset is to leverage our ability to visually identify interesting items patterns, by using Information Visualization (InfoVis) techniques. In this lesson we will focus on how Information Visualization can be effectively used to make sense of time-dependent data, such as streams. We will cover the following topics:
|
 |
Miguel Coimbra is currently a PhD student at Instituto Superior Técnico, hosted as a researcher at INESC-ID. He is currently researching distributed graph processing, in the scope and with the support of the Distributed Systems Group (GSD) and the Decision Support Systems (IDSS) laboratory. |
Lesson 4 Introduction to Stream Processing with Apache Flink This talk will introduce and detail the architecture and internal mechanisms of Apache Flink that make it a suitable basis for easily developing stream processing-based applications. Quoting from https://flink.apache.org/: Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams.Flink includes several APIs for creating applications that use the Flink engine:
Flink also bundles libraries for domain-specific use cases:
|
|
|
Alberto Cunha (IST) is professor at IST. He was a former researcher at INESC were he was involved in the design, development, and technology transfer, of innovative systems for office automation and electronic ticketing. He was member of the BoD of the Aitec-Link group with particular responsibility in the design of solutions and products for the Transports and Mobility sector. In 2009 he co-founded YouMove-Card4Business which developed, and presently maintains, many of the electronic ticketing systems for public transport in Portugal. From 2010 to 2013 he was member of the BoD of Taguspark, the main Science and Technology Park in Portugal, responsible for the bootstrap and operation of Taguspark business Incubator for technology-based startups. |
Lesson 5 Cyber-Physical Systems, IoT, and Embedded Systems Electronics and sensor technologies enable mobile and personal devices and equipment (smartphones, smartcards and tags) with considerable computing and communication power, and will enrich our surrounding environment with sensory and reactive capabilities. The orchestration of all this potential, integrating Internet-based as well as specialized heterogeneous sub-systems, is the foundation of cyber-physical systems able to adapt in time to the context of use.
Finally we will analyze some cases of application of these technologies to monitor human activities and services, and to create responsive and energy-efficient urban environments. |
Laboratory:
Laboratory with the collaboration of:
|
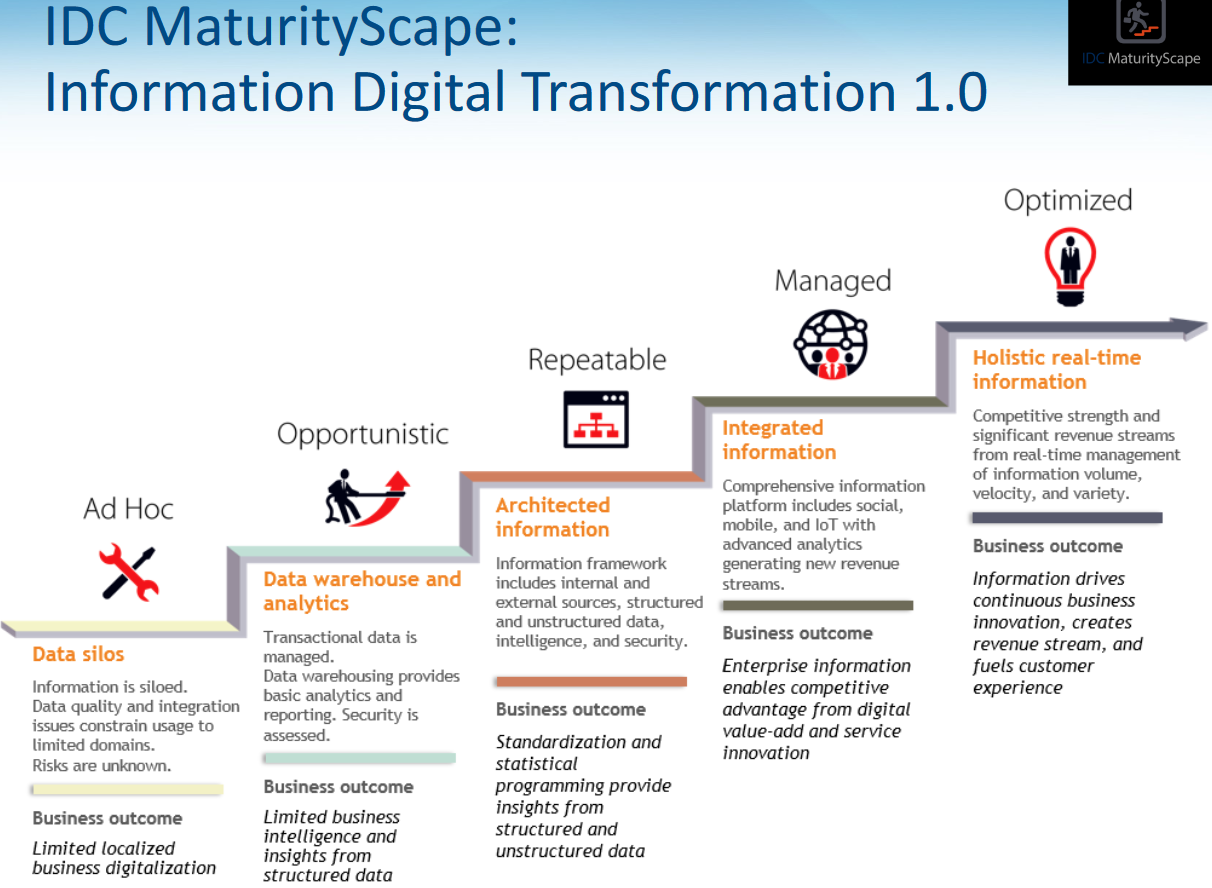
About the IDC Maturity Scape...
About the Penthao software...About the Tableau software...
|
|